
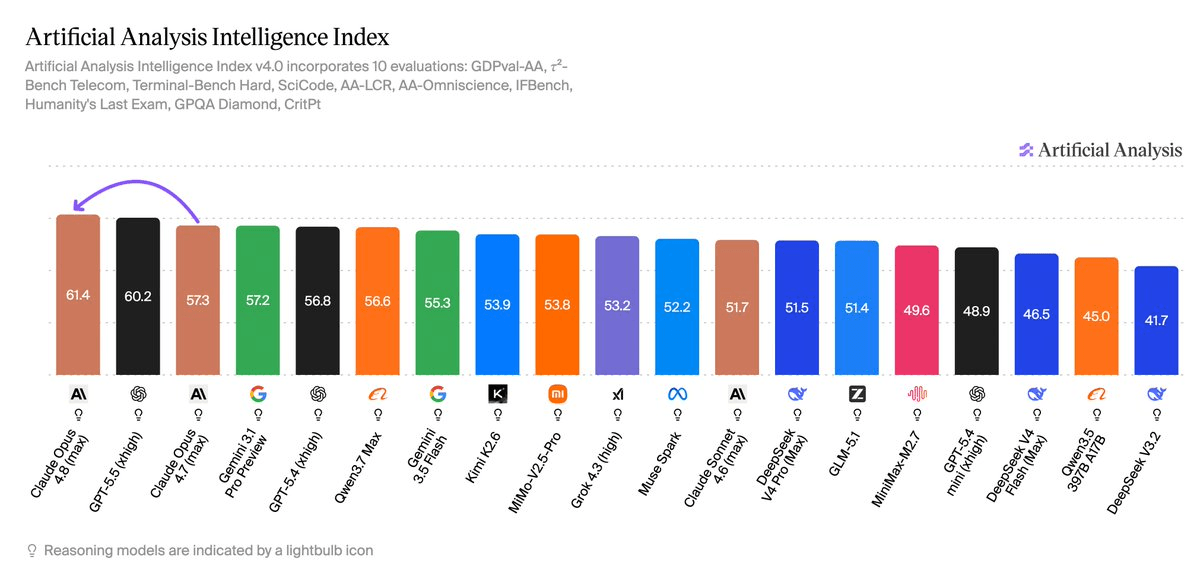
Anthropic just reclaimed the top spot in the frontier model race. Claude Opus 4.8 landed as the new leader on the Artificial Analysis Intelligence Index, scoring 61.4 , a 4.1-point jump from Opus 4.7 and 1.2 points ahead of GPT-5.5, the previous leader. The gains are concentrated where it matters most for production AI: long-horizon agentic tasks, scientific reasoning, and real-world knowledge work.
The numbers that matter
Opus 4.8 is an upgrade to Anthropic's flagship model with better coding and knowledge work skills, all for the same price as its prior version. That last part is worth emphasizing , no price increase for a meaningful capability jump. Here is the full scorecard:
- Artificial Analysis Intelligence Index: 61.4 (+4.1 from Opus 4.7, +1.2 ahead of GPT-5.5)
- GDPval-AA (knowledge work): 1,890 Elo , 121 points ahead of GPT-5.5's 1,769, implying a ~67% head-to-head win rate
- SWE-Bench Pro (agentic coding): Opus 4.8 at 69.2% vs GPT-5.5 at 58.6% vs Gemini 3.1 Pro at 54.2%
- Humanity's Last Exam (multidisciplinary reasoning): Opus 4.8 leads both competitors with and without tools
- Finance Agent v2: Opus 4.8 at 53.9%, edging GPT-5.5's 51.8%
- Terminal-Bench Hard: +6.8 points vs Opus 4.7; though GPT-5.5 still holds a slight edge in terminal-heavy workflows
Pricing for Claude Opus 4.8 when not in fast mode remains at $5 per million input and $25 per million output tokens. Fast mode allows it to work at 2.5x the speed while being three times cheaper than it was for previous models. The context window stays at 1 million tokens, matching Opus 4.7.
Where Claude finally caught up
One of the most notable storylines in this release is scientific reasoning. Previous Claude Opus versions consistently trailed OpenAI and Google on hard academic benchmarks , a gap that made Anthropic's models feel like the "practical" choice rather than the "smartest" choice. Opus 4.8 closes that gap decisively.
Anthropic highlighted improvements in model honesty, noting that Opus 4.8 is more likely to acknowledge when it lacks sufficient information and less likely to make unsupported claims. And on the AA-Omniscience hallucination benchmark, evaluations showed Opus 4.8 is around four times less likely than its predecessor to allow flaws in code it generated to go unremarked. That kind of calibration matters enormously in unattended agentic pipelines where a silent failure can cascade.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves