
Anthropic just did something it said it might never do: put a Mythos-class model in the hands of the general public. Claude Fable 5 is the first publicly available model from the company's top-tier Mythos family, and it arrives with a novel safety architecture that routes dangerous queries away from the model entirely. The result is a frontier model with a built-in ceiling, and a preview of how AI labs might handle the next generation of genuinely dangerous capabilities.
The name itself is a clue. Fable comes from the Latin fabula, meaning "that which is told" , a sibling to mythos. The two names describe the same underlying model, separated only by what it's allowed to do. Fable 5 is Mythos 5 with the safety classifiers on. Mythos 5 is Fable 5 with some of those classifiers lifted, available only to a restricted set of vetted partners.
Two months in the making
Launched as a preview in April, Mythos was initially limited to a handful of partners due to cybersecurity concerns. Anthropic began Project Glasswing, releasing the first Mythos-class model to only a limited group of cyber defenders and critical software infrastructure providers, stating that they hoped to eventually release Mythos-level capabilities to all users, so long as they had developed new safeguards strong enough to reliably prevent misuse. That moment has now arrived.
Last week, Anthropic expanded access to hundreds of organizations across 15 countries, again focusing on organizations that manage critical infrastructure. Several cybersecurity and tech companies have since announced their participation in the project, including Dragos, Tenable, TrendAI (Trend Micro), Netskope, BeyondTrust, Rubrik, BT, Intercontinental Exchange, and Hitachi. Today, the model opens to everyone.
What the model can actually do
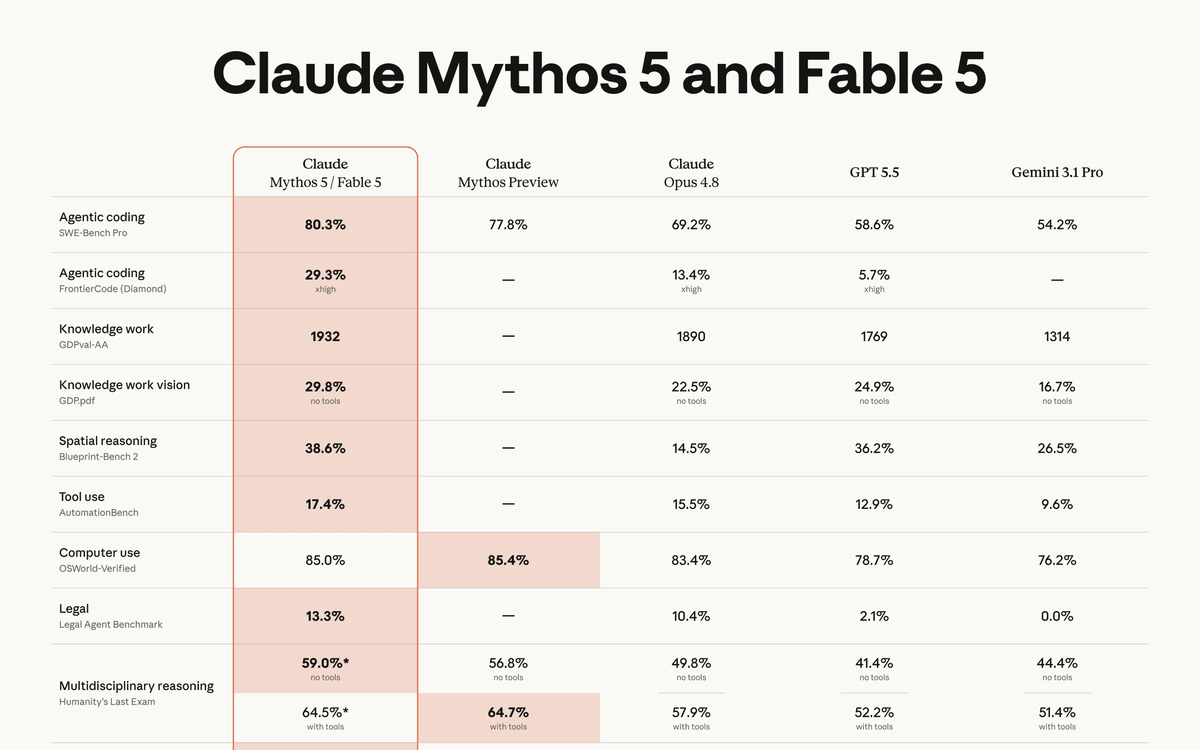
Fable 5's capabilities exceed those of any model Anthropic has ever made generally available. It is state-of-the-art on nearly all tested benchmarks of AI capability, showing exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Fable 5's lead over other models.
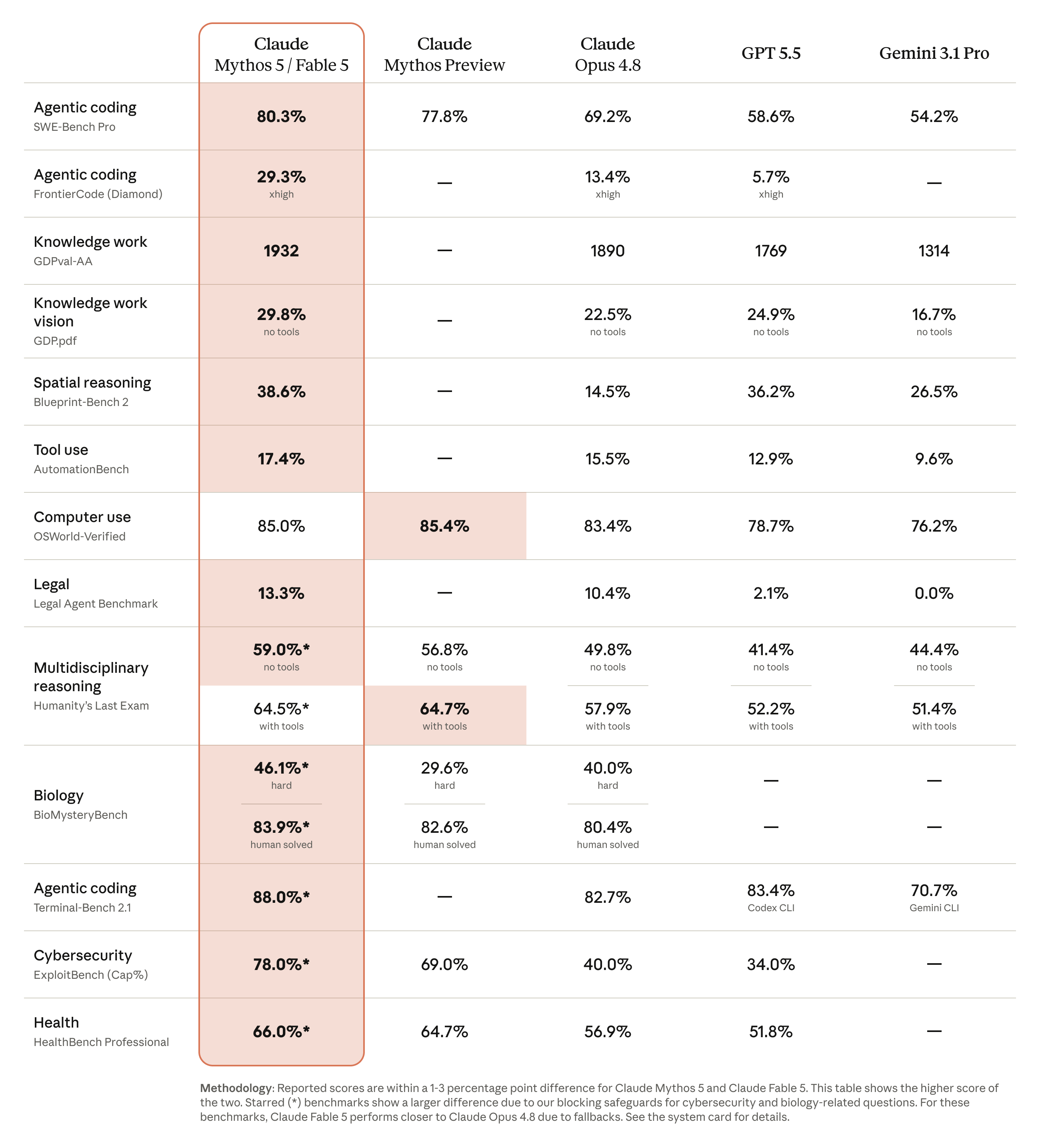
The coding results are particularly striking. During early testing, Stripe reported that Fable 5 compressed months of engineering into days. In a 50-million-line Ruby codebase, the model performed a codebase-wide migration in a day that would otherwise have taken a whole team over two months by hand. On SWE-Bench Pro, Anthropic's internal testing found that its new models correctly solved 80.3% of questions, compared to 69.2% for Claude Opus 4.8 and 58.6% for OpenAI's GPT-5.5.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves