
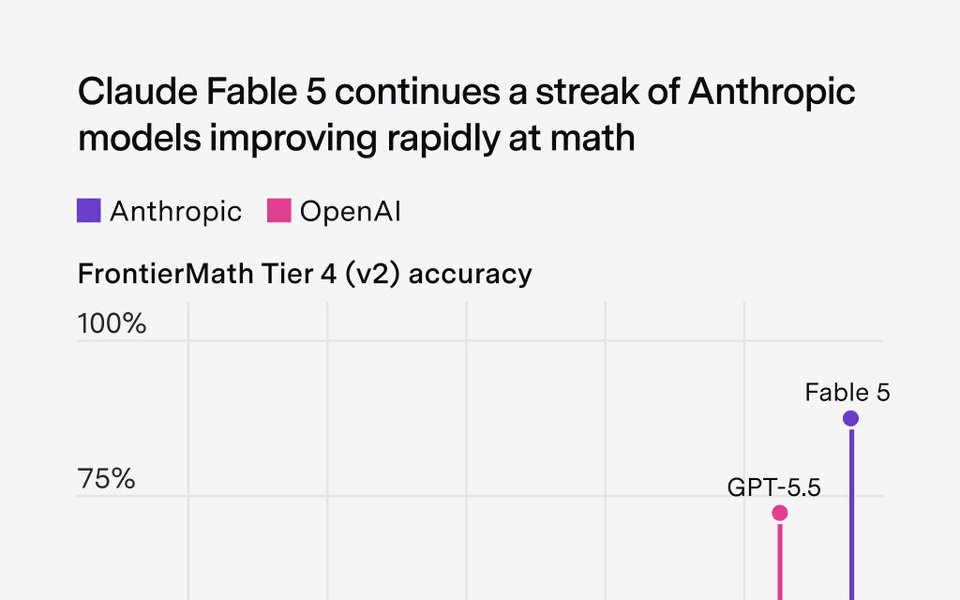
When FrontierMath launched in late 2024, every AI model tested solved fewer than 2% of its problems. That number just became a historical footnote. Claude Fable 5, Anthropic's newest and most capable model, now holds the top spot on the leaderboard, reaching 87% on Tiers 1–3 and 88% on Tier 4 , a streak of rapid improvement in Anthropic models' math capabilities. The results were published by Epoch AI, the independent research organization that runs the benchmark.
The benchmark that was built to break AI
FrontierMath is not a typical math test. The questions cover most major branches of modern mathematics , from computationally intensive problems in number theory and real analysis to abstract questions in algebraic geometry and category theory. Solving a typical problem requires multiple hours of effort from a researcher in the relevant branch of mathematics, and for the upper end questions, multiple days.
It was built with more than 60 mathematicians, including contributors holding 14 International Mathematical Olympiad gold medals and a Fields Medalist among the advisors. The benchmark is also deliberately "guessproof" , a term the team uses to mean that problems have large numerical answers or complex mathematical objects as solutions, with less than a 1% chance of guessing correctly without the mathematical work.
The four tiers escalate sharply in difficulty:
- Tiers 1–3: 350 original mathematics problems spanning from challenging university-level questions to problems that may take expert mathematicians days to solve.
- Tier 4: 50 extremely difficult problems developed as short-term research projects by mathematics professors and postdoctoral researchers , solving these tasks would provide evidence that AI can perform the complex reasoning needed for scientific breakthroughs in technical domains.
For each FrontierMath question, the model needs to submit a Python function answer() that returns the answer , often an integer or a SymPy object. This means models can use Python as a computational tool, but the reasoning still has to be genuinely mathematical.
A benchmark update that changes everything , and nothing


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves