
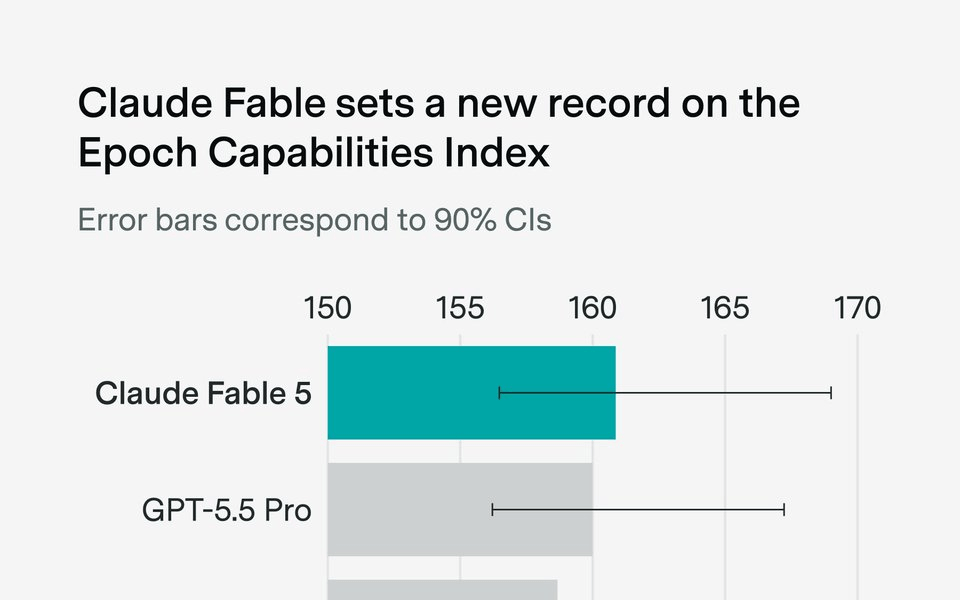
Anthropic has spent the better part of a year watching OpenAI hold the top spot on the Epoch Capabilities Index. That streak just ended. Epoch AI's independent tracking data shows Claude Fable 5 hitting a score of 161 on the ECI , one point ahead of GPT-5.5 Pro's 159 , the first time Anthropic has led the index in over a year.
What the ECI actually measures
The ECI is not a single test. It combines scores from many different AI benchmarks into a single general capability scale, allowing comparisons between models even over timespans long enough for individual benchmarks to reach saturation. Think of it as a composite leaderboard that stays meaningful even as any one benchmark gets solved.
The ECI uses a statistical model similar to Item Response Theory, under which models are deemed more capable if they score well on difficult benchmarks, and benchmarks are deemed more difficult if capable models are unable to score highly on them. Currently, the ECI uses 1,123 distinct evaluations, covering 147 models and 39 underlying benchmarks. That breadth is what makes a one-point lead meaningful , it is not a fluke on a single test.
Math is where Anthropic flipped the script
Historically, Anthropic models have trailed the frontier on the ECI while punching above their weight on software benchmarks. Fable 5 changed the pattern by taking the lead specifically on math. That shift is visible in the FrontierMath numbers:


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves