
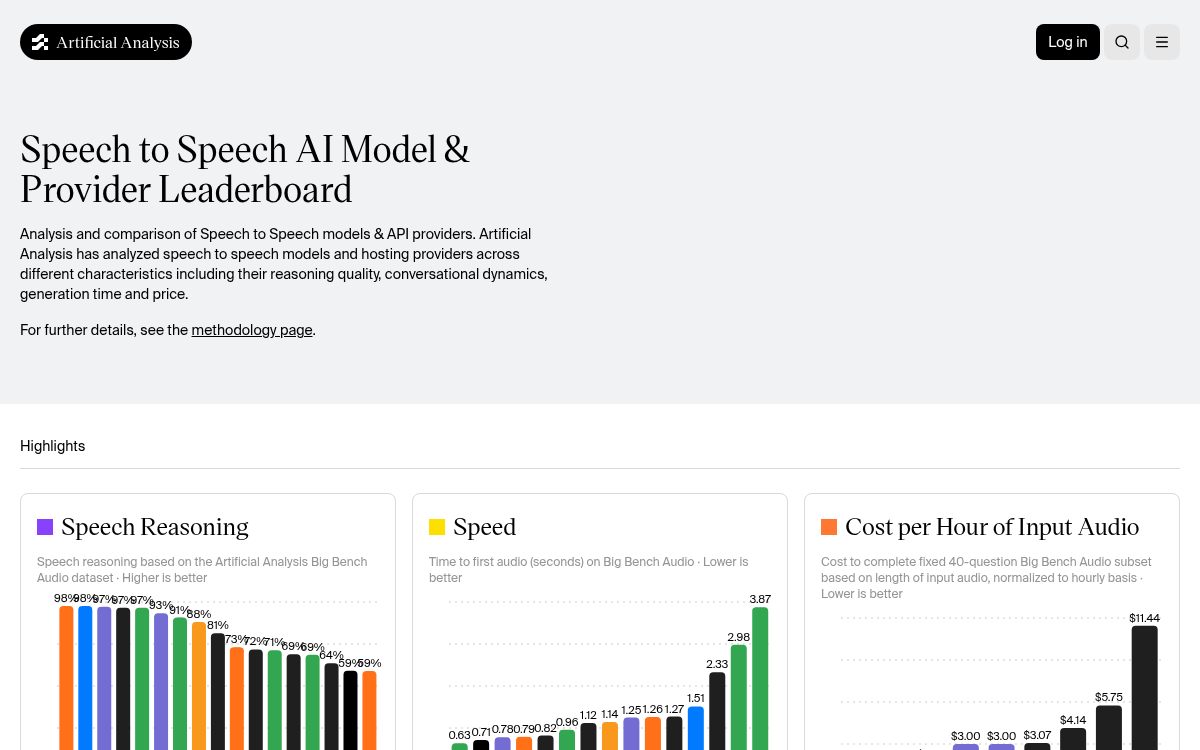
Alibaba's Tongyi Lab just landed three simultaneous top rankings on the Artificial Analysis speech-to-speech leaderboard, the most comprehensive independent benchmark for real-time voice models. Their Fun-Realtime-AudioChat model took first place in both speech reasoning (97.6% on Big Bench Audio) and conversational dynamics (97.8% on Full Duplex Bench), while Fun-Realtime-ASR claimed the top spot in transcription accuracy with an AA-WER (word error rate index) of just 1.8%. These aren't narrow wins either: GPT-Realtime-2 (High) scores 96.6% on reasoning and 95.3% on conversational dynamics, meaning Fun-Realtime-AudioChat beats OpenAI's best on both axes simultaneously.
Two models, one story
The Fun series is really two distinct products solving different problems. Fun-Audio-Chat is an open-source end-to-end speech-to-speech model developed by Alibaba's Tongyi Bailing team that can understand and respond to voice input directly, without needing separate ASR, LLM, and TTS components. Fun-ASR, on the other hand, is a dedicated transcription engine. Fun-ASR v1.5 is a 30B-parameter MoE-based end-to-end speech recognition model trained on tens of millions of hours of real speech data, systematically advancing language coverage, dialect recognition depth, and text output quality.
The distinction matters for builders. Fun-Audio-Chat is the conversational layer: you talk to it, it talks back, and it understands your emotion. Fun-ASR is the transcription workhorse: you pipe audio in, you get accurate, well-formatted text out. Both are now available via Alibaba Cloud's Model Studio API.
The architecture that makes it tick
Existing joint speech-text models face critical challenges: the temporal resolution mismatch between speech tokens (typically 25Hz) and text tokens (approximately 3Hz) dilutes semantic information and hinders the full utilization of the LLM's core capabilities, while continual pre-training often leads to catastrophic forgetting of the text LLM's knowledge. Fun-Audio-Chat was built specifically to solve these two problems.
The core innovation is called Dual-Resolution Speech Representations (DRSR). The Shared LLM processes audio at an efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Think of it as a two-tier pipeline: the backbone quickly grasps meaning at low resolution, and a specialized head adds the fine-grained acoustic detail needed for natural-sounding output.


Don't miss what's next in AI
Join 300,000+ engineers and researchers who get the signal, not the noise.
- Full access to in-depth AI research breakdowns
- Be the first to know what's trending before it hits mainstream
- Daily curated papers, repos, and industry moves